Akamai Bot Manager Premier en 2026: arquitectura, señales, ML y tácticas de operación
Contenido del artículo
- Introducción: por qué es crucial entender akamai bot manager premier ahora
- Fundamentos: conceptos y terminología básica
- Profundización: arquitectura y detección ml de akamai bot manager premier
- Práctica 1: construyendo un mapa de señales y escenarios de medición
- Práctica 2: pruebas legítimas y qa considerando políticas anti-bots
- Práctica 3: emulación de cliente para análisis y pruebas funcionales
- Práctica 4: capa de red — ip móviles con cgnat frente a centros de datos, rotación y control de calidad
- Práctica 5: estrategias para diferentes categorías de sitios
- Práctica 6: métricas de calidad y control operativo
- Práctica 7: patrones de infraestructura para integración y entornos de prueba
- Errores típicos y cómo evitarlos
- Herramientas y recursos para el trabajo
- Casos y resultados: cómo funciona en la práctica
- Faq: preguntas difíciles y respuestas reflexivas
- Conclusión: estrategia a 12 meses
Introducción: por qué es crucial entender Akamai Bot Manager Premier ahora
Hoy, en 2026, el tráfico automatizado no es solo un "fondo" en la web, sino un factor clave que influye en los métricas de ingresos, presupuestos publicitarios, SLA de aplicaciones y seguridad de datos del usuario. Las plataformas anti-bots como Akamai Bot Manager Premier están integradas en las interfaces de los bancos en línea, marketplaces, sistemas de reserva de boletos de avión y grandes operadores de apuestas. Ellas determinan quién accede al sitio y cómo: sin fricciones, con verificación suave o mediante llamados multinivel y políticas dinámicas. En este material, desglosaremos Akamai Bot Manager Premier por capas: arquitectura y canales de implementación, mapa de señales recolectadas, mecánica de detección ML, matices de perfilado de IP móviles con CGNAT en comparación con rangos de centros de datos, así como enfoques prácticos para la correcta prueba, QA y scraping analítico dentro del marco legal y de relaciones contractuales. Nuestro objetivo es brindarte, como líder técnico y de producto, una guía unificada que te ayude a tomar decisiones informadas, construir una estrategia anti-bots más efectiva y organizar adecuadamente los escenarios de prueba considerando las limitaciones de privacidad actuales y las tendencias de 2026.
Fundamentos: conceptos y terminología básica
Roles y dominios de aplicación
- E-commerce: protección de precios y surtido contra scraping agresivo, protección del carrito y checkout, lucha contra registros falsos y fraudes en promociones.
- Bancos: protección de la autenticación, verificación de la integridad de sesiones, contrarrestar el credential stuffing y los intentos automáticos de ingeniería social.
- Boletos de avión: equilibrio entre la apertura de tarifas y la protección contra monitoreo de precios masivo, que aumenta costos y distorsiona la demanda.
- Casas de apuestas: control sobre registros y abuso de bonos, protección de líneas y cuotas, asegurando la honestidad y el cumplimiento de reglas.
Términos clave
- Señales (signals): características medibles de la conexión, cliente y comportamiento del usuario: desde huellas TLS y prioridades HTTP/2 hasta trayectorias del mouse y métricas temporales de eventos.
- Huella (fingerprint): combinación reproducible de señales que identifica el dispositivo/entorno de software a lo largo de una o varias sesiones.
- CGNAT: Carrier-Grade NAT, donde decenas y cientos de abonados de un operador de telecomunicaciones salen a Internet a través de un IP público común. Para la detección de bots, este es un indicador importante de la naturaleza "móvil" de la dirección.
- Good bots vs Bad bots: los primeros son automatización útil (por ejemplo, robots afiliados acordados), los segundos son indeseables (scraping no autorizado, escenarios de fraude, ataques masivos de fuerza bruta).
- Acciones (mitigations): desde "allow" hasta suaves "challenges", tarifas, retrasos dinámicos, degradación funcional diferenciada y bloqueos estrictos.
Por qué es difícil el contenido sobre gestión de bots
El anti-bots es un cruce de pilas de red, APIs web, análisis conductual y aprendizaje automático. Un error en la interpretación de una señal puede llevar a bloqueos erróneos, y una simplificación excesiva hace que el sistema sea "vulnerable". Por lo tanto, es importante hablar tanto sobre "qué" como sobre "cómo": qué señales se recolectan, cómo se agregan y en qué casos son más informativas.
Profundización: arquitectura y detección ML de Akamai Bot Manager Premier
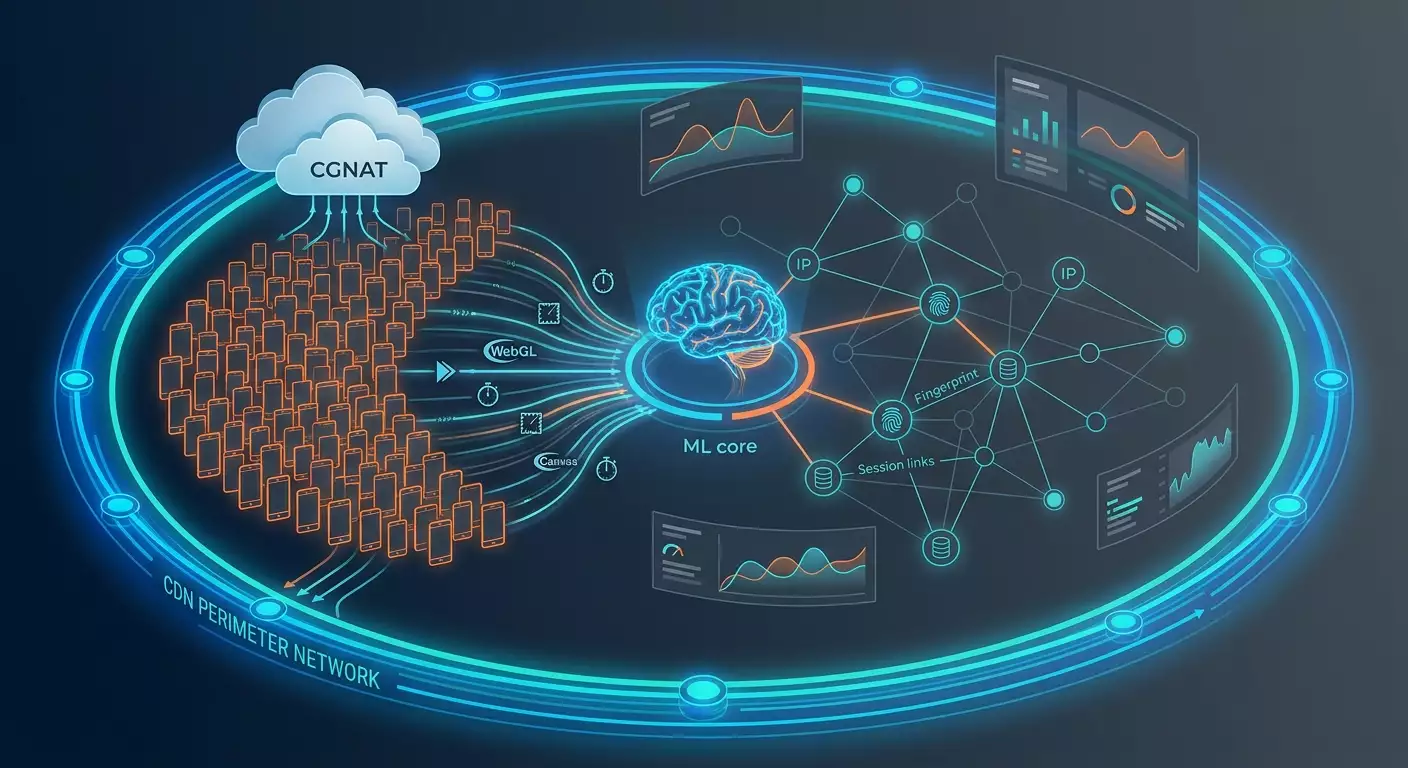
Arquitectura por capas
- Perímetro y capa CDN: integración a nivel de plataforma de entrega de contenido. Análisis de TCP/TLS, ALPN, prioridades HTTP/2 y HTTP/3, parámetros QUIC y métricas de inestabilidad de red.
- Sensor cliente: agentes de JavaScript y WebAssembly que recogen señales de APIs web disponibles: Navigator, WebGL, Canvas, AudioContext, MediaDevices, cronometrías, eventos de entrada, patrones de desplazamiento, actividad en foco, renderizado y micro-retrasos.
- SDK móviles: módulos opcionales para iOS y Android con enfoque en la certificación del entorno, integridad de la aplicación, métricas conductuales básicas e indicadores de red.
- Corredor de soluciones del servidor: procesamiento en tiempo real de señales, correlación con perfiles IP/ASN/prefixes, actualización de reputaciones y listas, interacción con WAF y sistemas downstream.
- Almacén de características: enriquecimiento, normalización, versionado de características, control anti-drift y preparación de features para scoring en tiempo real y reentrenamiento offline.
- Mecanismo de políticas: reglas configurables considerando categoría empresarial (bancos, e-commerce, aviación, casas de apuestas), geografía, hora del día, estado de campañas y estacionalidad.
Mapa de señales: de bajo nivel a conductuales
Redes y transporte
- Huella TLS (JA3/JA4 similares): conjuntos de cifrados, extensiones, órdenes de cliente y servidor, características del handshake.
- Prioridades HTTP/2 y dinámica de tramas: esquemas de multiplexión, profundidad de colas, reacciones a bloqueos de ventanas.
- HTTP/3/QUIC: Connection IDs, pérdida inicial, recuperación de pérdidas, perfil QPACK, variabilidad de RTT.
- Heurísticas TCP/IP: MSS, ventanas, Timestamp, SACK, combinaciones raras de flags, así como distribución de puertos en CGNAT.
- ASN/geo/prefix: correlación de AS móviles, centros de datos, redes corporativas; intersecciones con pools conocidos de automatización.
Cliente y sistema
- Client Hints y User-Agent: en 2026, la dependencia se ha desplazado hacia CH; incoherencias entre UA y CH son un desencadenante significativo.
- WebGL/Canvas/Audio: estabilidad de huellas de renderizado, ruido, controladores, señales de GPU, comportamiento en escenas complejas.
- Navigator/HardwareConcurrency/Memory: verificaciones cruzadas de núcleo-memoria-tipo de dispositivo y perfil de consumo de energía.
- Temporizaciones de renderizado: secuencia de requestAnimationFrame, frecuencia de cuadros, micro-retrasos GC, jitter de EventLoop.
- Almacenes y marcadores: cookies, Storage, versiones indexadas, semántica de rekeying entre pestañas y tiempo.
Conductuales
- Trayectorias del cursor y desplazamiento: continuidad, inercia, paradas "naturales", reacción a elementos imprevisibles.
- Cadencia del teclado: intervalos, errores, correcciones, comportamiento de IME y combinaciones de teclas.
- Patrones de navegación: profundidad de visualización, regresos, densidad de interacciones, pausas antes de la acción objetivo.
Detección ML en 2026
- Scoring multinivel: verificación lineal rápida, luego GBDT/red neuronal sobre características agregadas y, de ser necesario, un modelo secuencial sobre eventos (transformador/representaciones diferenciales).
- Características gráficas: relaciones IP-huella-cookie-dispositivo con métricas anti-simbolismo de resistencia. Detección de "familias" de bots.
- Drift y adaptación: monitoreo online de métricas de drift, retrocesos y avanzamientos manuales y semi-automáticos, validación A/B constante.
- Políticas contextuales: el mismo scoring puede dar diferentes acciones dependiendo de la página (login vs catálogo) y categoría del cliente (nuevo vs leal).
Práctica 1: Construyendo un mapa de señales y escenarios de medición
¿Por qué es necesario un mapa de señales?
El mapa de señales es un inventario de qué señales son importantes para tu vertical y tus escenarios de usuario. Ayuda a alinear la política anti-bots entre seguridad, producto y marketing, para disminuir el riesgo de bloqueos de usuarios reales.
Pasos
- Define los caminos críticos: login, registro, búsqueda, carrito, pago, métodos API. Para bancos—autenticación y transferencias; para boletos de avión—búsqueda y reserva; para casas de apuestas—registro y manejo de fondos.
- Correlaciona señales: dónde son más importantes las métricas conductuales y dónde las huellas de bajo nivel. Por ejemplo, en login y pago las señales conductuales son especialmente sensibles.
- Establece KPI: tasas de bloqueo objetivo, proporción de desconocidos, frecuencia de desafíos, tiempo promedio hasta la solución, proporción de escalaciones a revisión manual.
- Recolecta datos de tráfico en vivo: incluyendo telemetría de errores, reingresos, métricas en cada paso del embudo.
- Define cohortes de control: regiones, nuevos/vueltos, dispositivos/navegadores, redes móviles/fijas.
Checklist del mapa de señales
- Inventario de señales utilizadas y responsable de su interpretación.
- Límites de corrección: qué discrepancias se consideran normales en tu audiencia.
- Planes de pruebas para cada camino crítico.
- Presupuesto para falsos positivos y intervalos de revisión.
Práctica 2: Pruebas legítimas y QA considerando políticas anti-bots
Marco ético y legal
Cualquier pruebas, carga, scraping y automatización deben llevarse a cabo sobre bases legales y coordinaciones. Para sitios de terceros—permiso por escrito o contrato; para tus sistemas—coordinación con seguridad y operación. Respeta los términos de uso, no causes daño y no imites usuarios donde no hay un objetivo de prueba.
Proceso paso a paso
- Coordinación con el propietario del perímetro: ventana de prueba, límites RPS, lista de IP/ASN, escenarios y datos para identificación en logs.
- Configuración del entorno: stand o producción con menor impacto; para producción—políticas "suaves", whitelisting de cuentas de prueba y etiquetas de solicitudes.
- Telemetría: habilitar registro extendido de eventos de Bot Manager y proquear logs en SIEM/observabilidad para verificación cruzada.
- Puntos de control: registrar falsos positivos/falsos negativos, correlacionar con señales y acciones (allow/challenge/block).
- Retrospectivas: analizar casos complejos, actualizar el mapa de señales y el entrenamiento de modelos si participas en co-desarrollo.
Sugerencias prácticas
- Utiliza marcadores de pruebas en las solicitudes (encabezados especiales y protocolos de advertencia) para simplificar el análisis.
- Para reproductibilidad—registra versiones de navegadores, SO, tipo de conexión.
- Ten cuidado con la navegación asíncrona: registra pasos y tiempos.
Práctica 3: Emulación de cliente para análisis y pruebas funcionales
Principios de correcta emulación
- Consistencia en la pila: plataforma, versión de navegador, fuentes, idioma, zona horaria, formato horario y distribución del teclado deben estar alineados.
- Tiempo natural: entrada, desplazamiento y clics a un ritmo comparable con la interacción humana, sin picos abruptos ni patrones sintéticos.
- Perfiles de API Web estables: huellas de renderizado y huellas de audio no deben fluctuar caóticamente entre pasos de la sesión.
- Sesiones y cookies: mantener el contexto entre páginas y pestañas donde se espera.
Pasos de configuración para pruebas funcionales
- Selecciona un dispositivo de referencia: determina el navegador objetivo y la plataforma de tu audiencia principal.
- Verifica la huella: genera y registra parámetros de referencia a través de una herramienta de generación de huellas de navegador, luego asegúrate de que el entorno de prueba reproduzca valores comparables.
- Perfil de red: establece retardos y jitter característicos de la audiencia, para que los tiempos de eventos sean realistas.
- Paso de reproducción: registra la secuencia de acciones y retardos, para asegurar la repetibilidad de los resultados y el análisis en los logs de anti-bots.
Checklist de emulación
- UA y Client Hints alineados, zona horaria correspondiente a la geografía.
- Pantalla y densidad de píxeles comparables con el dispositivo objetivo.
- Inicialización de WebGL/Canvas predecible, renderizado no "salta" entre visitas sin razón.
- Señales de entrada se producen sin velocidad sobrehumana.
Práctica 4: Capa de red — IP móviles con CGNAT frente a centros de datos, rotación y control de calidad
Por qué los IP móviles con CGNAT son percibidos con más lealtad
- Reputación ASN: los operadores móviles llevan una reputación "básica de usuario", mientras que algunos centros de datos correlacionan con automatización y scripts.
- Dinámica CGNAT: un IP compartido para múltiples abonados crea un alto fondo "natural" de actividad legítima; las señales se correlacionan con usuarios reales.
- Heurísticas de red: oscilaciones RTT característicos, jitter, características de red inalámbrica y distribución de puertos se perciben como orgánicos.
Cuándo son justificables las IP de centros de datos
Para pruebas internas en un entorno controlado, cuando la previsibilidad y estabilidad de rutas son importantes. Integraciones externas con políticas de whitelist claras también suelen realizarse en direcciones DC por acuerdo.
Rotación y robustez
- Rotación por temporizador/API: evita una frecuencia excesiva de cambio de direcciones para escenarios de múltiples pasos. La sesión debe ser continua.
- Estabilidad geo y ASN: para la comparabilidad de experimentos, utiliza un solo país y, si es posible, un solo operador.
- Calidad de la conexión: monitorea pérdidas, retrasos y velocidad, para excluir anomalías de red de las causas de fallos.
Nota práctica
Para el monitoreo legítimo, QA y tareas analíticas con contexto móvil real, son convenientes los proxies móviles basados en SIM. Es importante que el proveedor soporte protocolos HTTP(S) y SOCKS5 simultáneamente, rotación por temporizador y a través de API, amplia geografía y soporte 24/7. Un ejemplo adecuado de tal servicio sería MobileProxy.Space: tarjetas SIM reales, más de 218 millones de IP en más de 53 países, rotación flexible por temporizador, API y enlace, 3 horas de prueba gratuita y soporte 24/7. Para la primera compra, hay un código promocional YOUTUBE20 con un 20% de descuento.
Práctica 5: Estrategias para diferentes categorías de sitios
Bancos
- Foco: autenticación y operaciones. Alta sensibilidad a la biometría conductual y la integridad del dispositivo.
- Tácticas de prueba: cargas mínimas, ventanas de prueba claras, IP fijas y escenarios de login acordados.
E-commerce
- Foco: catálogo, carrito, promociones. Equilibrio entre UX y contrarrestar el scraping masivo.
- Tácticas: rotación A/B de políticas en secciones menos arriesgadas, telemetría del impacto de desafíos en la conversión.
Boletos de avión
- Foco: búsqueda y reserva; protección de tarifas y cachés de precios.
- Tácticas: restricciones en la frecuencia de solicitudes similares, verificación intensificada durante búsquedas masivas en fechas contiguas.
Casas de apuestas
- Foco: registro, bonos, líneas de apuestas.
- Tácticas: verificación intensificada de nuevos dispositivos, patrones conductuales antes y después del registro, políticas dinámicas para eventos picos.
Práctica 6: Métricas de calidad y control operativo
Qué medir
- Proporción de tráfico sospechoso: tendencias por segmentos (ASN, región, dispositivo).
- Falsos Positivos/Negativos: proporción de personas bloqueadas erróneamente y bots pasados por alto.
- Tasa de paso de desafíos: cuántas veces los usuarios legítimos pasan las verificaciones sin problemas.
- Impacto en el embudo: cambio en CR, carritos abandonados, rechazos en login.
Procesos
- Revisiones semanales: incidentes, picos, comparación con cohortes de control.
- Retrospectivas de modelos: análisis de drift de características, seguridad en la entrega de features.
- Colaboración: seguridad, producto, marketing y operación con dashboards unificados.
Práctica 7: Patrones de infraestructura para integración y entornos de prueba
Capas de integración
- Perímetro CDN/WAF: solución primaria y políticas ligeras para baja latencia.
- Aplicación: obtención de detalles para la lógica empresarial refinada en pasos críticos.
- Analítica: exportación de telemetría a almacenes de eventos y SIEM para correlación integral.
Entornos de prueba
- Staging: verificación de compatibilidad de sensores, estabilidad de huellas entre versiones.
- Configuraciones Canary: activación cuidadosa de nuevas reglas en parte del tráfico con comparación detallada de métricas.
- Pruebas Chaos: simulación de pérdidas de red y retrasos para entender la robustez de soluciones.
Errores típicos y cómo evitarlos
- Sobreajuste por incidentes individuales: lleva a un aumento de falsos positivos. Solución: valida con datos representativos.
- Ignorar el drift: señales y comportamiento de usuarios cambian. Solución: reevaluaciones regulares de reglas y modelos.
- Desacuerdo entre equipos: KPIs diferentes llevan a conflictos. Solución: matriz unificada de métricas y plan de implementación común.
- Rotación incorrecta de IP: cambios excesivos sin considerar sesiones arruinan escenarios. Solución: rotación considerando la duración de tareas.
- Inconsistencias aleatorias en la huella: lenguajes contradictorios/zona horaria/pantallas. Solución: listas de verificación de consistencia.
Herramientas y recursos para el trabajo
Internas
- Paneles de anti-bots: desglose por señales, acciones, modelos.
- Observabilidad: dashboards centrales de retardos, errores, capacidad.
- Acuerdos: regulaciones para pruebas, decisiones arquitectónicas, playbooks de incidentes.
Auxiliares
- Verificación de IP y DNS: asegúrate de que los parámetros de red correspondan a las expectativas de la audiencia objetivo y no contengan fugas de DNS para tus pruebas.
- Verificación de proxies: valida la disponibilidad, protocolos y retrasos básicos de nodos proxy antes de ejecutar escenarios.
- Calculadora de proxies y mapa de retardos: planifica presupuestos y selecciona regiones y operadores óptimos según RTT.
- Generador de huellas de navegador: registra el estándar y verifica la estabilidad del perfil durante los lanzamientos.
Es importante destacar que algunos de estos instrumentos están disponibles en el ecosistema de MobileProxy.Space: verificación de IP, DNS Leak Test, Proxy Checker, calculadora de proxies, mapa de retardos y generador de huellas de navegador que ayudarán a acelerar la preparación para las pruebas. Combinados con sus proxies móviles (HTTP(S) y SOCKS5 simultáneamente, rotación por temporizador, API y enlace), esto cubre la necesidad básica de infraestructura para un adecuado QA.
Casos y resultados: cómo funciona en la práctica
Caso 1: E-commerce y picos de scraping
Problema: aumento de solicitudes al catálogo, picos en gastos de CDN y degradación de búsqueda. Acciones: ajustamos el mapa de señales para el catálogo, aumentamos la priorización de HTTP/2 y patrones conductuales para listado, realizamos A/B en el 10% del tráfico. Resultado: reducción de solicitudes sospechosas del 38%, mantención de la conversión en el carrito, disminución de la latencia p95 en un 12% gracias a tarifas en vez de bloqueo total.
Caso 2: Banco y login vulnerable
Problema: oleada de credential stuffing. Acciones: mayor sensibilidad a incoherencias UA/CH, intensificación de la verificación de sesiones, desafíos suaves durante la noche para nuevos dispositivos en regiones sensibles. Resultado: reducción de inicios de sesión fallidos en un 44%, sin aumento en consultas al soporte gracias a verificaciones suaves.
Caso 3: Boletos de avión y monitoreo de precios
Problema: búsqueda masiva de fechas cercanas, carga excesiva en caché y meta-búsqueda. Acciones: políticas dinámicas por rangos de fechas y frecuencia; separación de escenarios en informativos y transaccionales. Resultado: reducción de solicitudes del 29% manteniendo un nivel estable de reservas exitosas, aumento en la precisión de pronósticos de demanda.
Caso 4: Casa de apuestas y abuso de bonos
Problema: grandes volúmenes de registros con ciclos de vida cortos. Acciones: añadimos un modelo secuencial sobre eventos antes y después del registro, fortalecimos la consistencia de la huella y verificación de señales móviles. Resultado: reducción del 35% de cuentas sospechosas, ahorro en bonos y disminución de la carga en moderación.
FAQ: preguntas difíciles y respuestas reflexivas
¿Cómo alinear políticas anti-bots y UX?
Establece niveles de sensibilidad por zonas de riesgo, mide el impacto en conversión y utiliza acciones suaves donde el bloqueo no sea crítico. La validación A/B regular es obligatoria.
¿Por qué los IP móviles a menudo son más "honestos" para pruebas de audiencia real?
Reflejan la dinámica de red "viva" de CGNAT y ASN móviles, que coincide con el comportamiento de parte de tus usuarios reales. Esto es especialmente útil para validar UX.
¿Se puede confiar completamente en señales conductuales?
No. Son fuertes en transacciones y logins, pero vulnerables a falsos positivos en redes inestables o disponibilidad. Se necesita una evaluación combinada.
¿Qué hacer ante picos de bloqueos erróneos?
Captura un volcado de telemetría, revierte las últimas reglas, activa políticas de mitigación y haz una retrospectiva sobre la cohorte con errores.
¿Cuál es el intervalo óptimo de rotación de IP?
Adáptalo a la duración del escenario. Para procesos de múltiples pasos, utiliza una dirección estable durante toda la sesión; cambia por tarea o según temporizador con margen de tiempo.
¿Es necesario unificar navegadores en las pruebas?
Sí, para reproducibilidad registra versiones y plataformas. Pero periódicamente verifica pilas alternativas para ver casos extremos de comportamiento.
¿Qué tan útiles son los mapas de retardos y verificaciones de DNS?
Ayudan a excluir anomalías de red como causa de conclusiones erróneas y a elegir geografías con menor riesgo de problemas.
¿Cómo trabajar con robots afiliados (good bots)?
Configura listas blancas, tokens y contratos; proporciona ventanas de llamados estables e identificación para auditoría transparente.
¿Cuál es la principal dificultad en la detección ML en 2026?
El drift y la actualizabilidad del comportamiento de los usuarios y atacantes: se requiere un almacenamiento estable de características, procedimientos anti-drift y rápida validación A/B de cambios.
Conclusión: estrategia a 12 meses
Una fuerte estrategia anti-bots en 2026 no es un conjunto de "secretos", sino una ingeniería sistemática: mapa de señales, alineación de equipos, scoring en ML a múltiples niveles y políticas flexibles, diferentes para login, catálogo, carrito y pago. Las prácticas de pruebas legítimas con ventanas alineadas y perfiles de red estables permiten mejorar la protección sin comprometer la UX. Los IP móviles con CGNAT a menudo se acercan más a la realidad del paisaje de usuarios, mientras que las direcciones de centros de datos siguen siendo útiles en escenarios controlados y listas blancas. Utiliza herramientas de verificación de IP, DNS y huellas, mapas de retardos y calculadoras para la previsibilidad de experimentos. Organiza retrospectivas mensuales, reevaluaciones trimestrales de modelos y mantén el enfoque en el impacto de las medidas sobre el embudo. Y sí, los servicios de infraestructura con tarjetas SIM reales y escalas de direcciones, como MobileProxy.Space, te ayudarán a construir cuidadosamente la capa de red para QA y monitoreo. No olvides su prueba de 3 horas y el código promocional YOUTUBE20: es útil cuando planificas presupuestos y pilotos en varios países con soporte simultáneo para HTTP(S) y SOCKS5, rotación por temporizador, API o enlace. Al final, todos ganan: la seguridad—por la precisión, el producto—por la conversión estable, y los usuarios—por una experiencia fluida y predecible.
