Akamai Bot Manager Premier w 2026: architektura, sygnały, ML i taktyka działania
Spis treści
- Wprowadzenie: dlaczego warto zająć się akamai bot manager premier właśnie teraz
- Podstawy: fundamentalne koncepcje i terminologia
- Głębokie zanurzenie: architektura i detekcja ml akamai bot manager premier
- Praktyka 1: budujemy mapę sygnałów i scenariuszy pomiarów
- Praktyka 2: legalne testowanie i qa z uwzględnieniem polityk antybotowych
- Praktyka 3: emulacja klienta do analiz i testów funkcjonalnych
- Praktyka 4: warstwa sieciowa — mobilne ip z cgnat w porównaniu do datacenters, rotacja i kontrola jakości
- Praktyka 5: strategie dla różnych kategorii stron
- Praktyka 6: metryki jakości i operacyjna kontrola
- Praktyka 7: wzorce infrastrukturalne integracji i testowe środowiska
- Typowe błędy i jak ich unikać
- Narzędzia i zasoby do pracy
- Przykłady i wyniki: jak to działa w praktyce
- Faq: trudne pytania i precyzyjne odpowiedzi
- Podsumowanie: strategia na 12 miesięcy
Wprowadzenie: dlaczego warto zająć się Akamai Bot Manager Premier właśnie teraz
W 2026 roku zautomatyzowany ruch stał się kluczowym czynnikiem wpływającym na wyniki finansowe, budżety reklamowe, SLA aplikacji oraz bezpieczeństwo danych użytkowników. Platformy antybotowe, takie jak Akamai Bot Manager Premier, są mocno zintegrowane z ofertami internetowymi banków, marketplace'ów, systemów rezerwacji biletów lotniczych oraz dużych operatorów zakładów. Określają one, kto ma dostęp do strony i w jaki sposób: bez konieczności interakcji, z delikatną weryfikacją lub poprzez wielowarstwowe wywołania i dynamiczne zasady. W tym materiale przyjrzymy się Akamai Bot Manager Premier w szczegółach: architekturze i kanałom wdrożenia, mapie sygnałów, mechanice detekcji ML, subtelnościom profilowania mobilnych IP z CGNAT w porównaniu do zakresów datacenters, a także praktycznym podejściom do właściwego testowania, QA oraz analitycznego parsowania w ramach obowiązującego prawa i relacji umownych. Naszym celem jest dostarczenie wam, jako liderom technicznym i produktowym, jednego poradnika, który pomoże podejmować uzasadnione decyzje, skuteczniej budować strategię antybotową oraz właściwie organizować scenariusze testowe z uwzględnieniem współczesnych ograniczeń dotyczących prywatności i trendów roku 2026.
Podstawy: fundamentalne koncepcje i terminologia
Rola i obszary zastosowania
- E-commerce: ochrona cen i asortymentu przed agresywnym scrapowaniem, zabezpieczenie koszyka i procesu zakupu, walka z fałszywymi rejestracjami i oszustwami podczas promocji.
- Banki: zabezpieczenie procesu autoryzacji, weryfikacja integralności sesji, przeciwdziałanie credential stuffing oraz zautomatyzowanym próbującym atakom socjotechnicznym.
- Bilety lotnicze: równowaga pomiędzy otwartością taryf a ochroną przed masowym monitorowaniem cen, co zwiększa koszty i zniekształca popyt.
- Bukmacherzy: kontrola rejestracji i nadużyć związanych z bonusami, ochrona kursów i zakładów, zapewnienie uczciwości i przestrzegania zasad.
Kluczowe terminy
- Sygnały (signals): mierzalne charakterystyki połączenia, klienta i zachowania użytkowników: od fingerprintów TLS i priorytetów HTTP/2 po trajektorie kursora i zmienne metryki czasowe.
- Fingerprint (odcisk): stabilnie reprodukowalna kombinacja sygnałów, identyfikująca urządzenie/środowisko oprogramowania w perspektywie jednej lub kilku sesji.
- CGNAT: Carrier-Grade NAT, kiedy dziesiątki i setki abonentów operatora telekomunikacyjnego korzystają z jednego publicznego IP. Dla antybota jest to ważny wskaźnik „mobilnego” charakteru adresu.
- Good bots vs Bad bots: pierwszy to użyteczna automatyzacja (np. uzgodnione roboty partnerskie), drugi to niepożądana (scrapowanie bez pozwolenia, scenariusze oszustw, masowe brute force).
- Działania (mitigations): od „allow” po łagodne „challenges”, tarpit, dynamiczne opóźnienia, zróżnicowana degradacja funkcji oraz surowe blokady.
Dlaczego treści dotyczące zarządzania botami są trudne
Antybot to skrzyżowanie stosów sieciowych, API klientów internetowych, analityki behawioralnej oraz uczenia maszynowego. Błąd w interpretacji jednego sygnału prowadzi do błędnych blokad, a nadmierne uproszczenie czyni system „dziurawym”. Dlatego ważne jest mówienie również o tym „co” oraz „jak”: jakie sygnały są zbierane, jak są agregowane i w jakich przypadkach są najbardziej informacyjne.
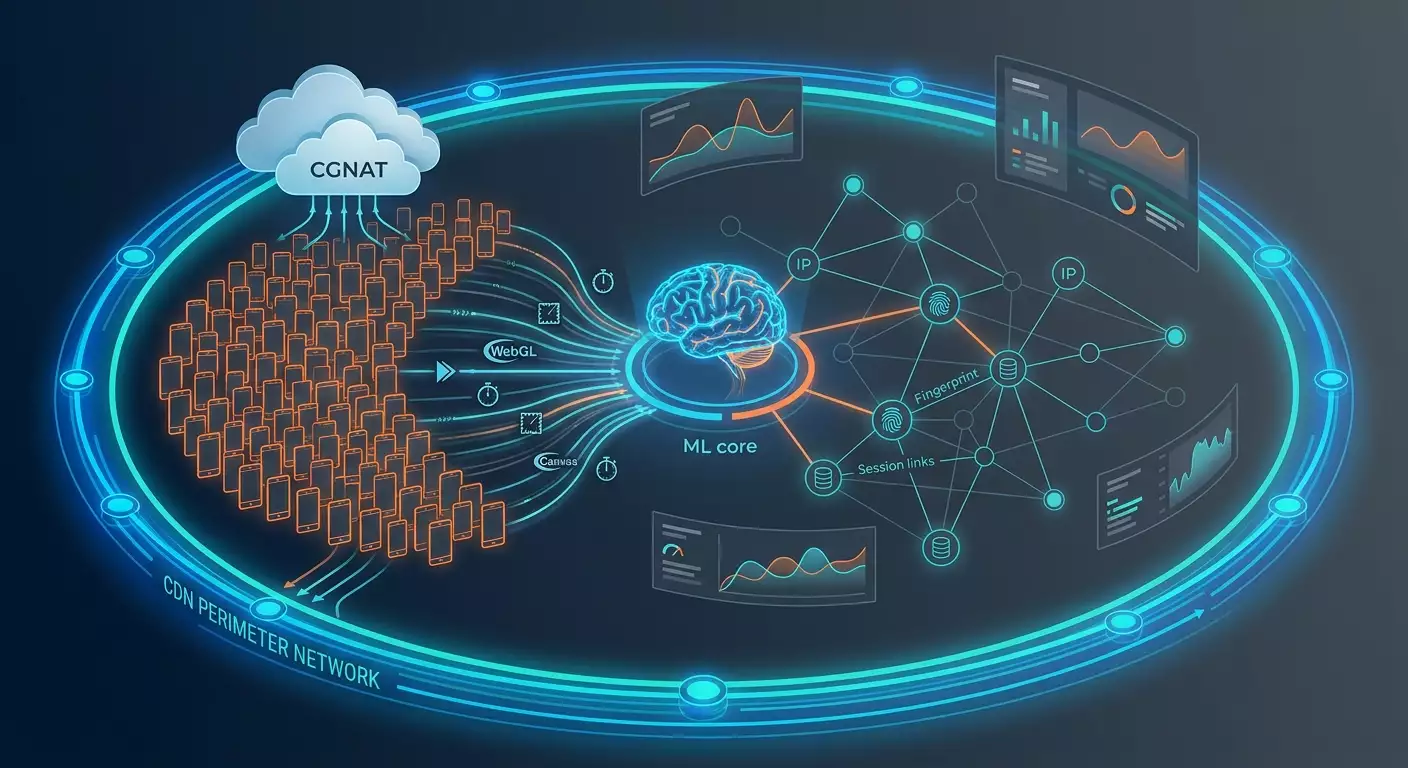
Głębokie zanurzenie: architektura i detekcja ML Akamai Bot Manager Premier
Architektura warstwowa
- Perimetr i warstwa CDN: integracja na poziomie platformy dostarczania treści. Analiza TCP/TLS, ALPN, priorytetów HTTP/2 i HTTP/3, parametrów QUIC oraz metryki niestabilności sieciowej.
- Czujnik klienta: agenci JavaScript i WebAssembly, którzy zbierają sygnały z dostępnych API Web: Navigator, WebGL, Canvas, AudioContext, MediaDevices, czas, zdarzenia wejściowe, wzorce przewijania, aktywność w fokusie, renderowanie oraz mikrooOpóźnienia.
- Mobilne SDK: opcjonalne moduły dla iOS i Android z naciskiem na certyfikację środowiska, integralność aplikacji, podstawowe metryki behawioralne oraz wskaźniki sieciowe.
- Serwerowy broker decyzji: przetwarzanie strumieniowe sygnałów, dopasowywanie z profilami IP/ASN/prefiksów, aktualizacja reputacji i list, interakcja z WAF i systemami downstream.
- Magazyn cech: wzbogacanie, normalizacja, wersjonowanie cech, kontrola antydryftowa i przygotowanie cech do online scoring i offline retraining.
- Mechanizm zasad: konfigurowalne reguły z uwzględnieniem kategorii biznesowej (banki, e-commerce, transport lotniczy, bukmacherzy), geograficznego, pory dnia, statusu kampanii oraz sezonowości.
Mapa sygnałów: od niskopoziomowych po behawioralne
Sygnały sieciowe i transportowe
- Fingerprint TLS (podobne do JA3/JA4): zestawy szyfrów, rozszerzeń, kolejności klienta i serwera, cechy uścisku dłoni.
- Priorytety HTTP/2 i dynamika ramek: schematy multiplexingu, głębokości kolejek, reakcje na blokowanie okien.
- HTTP/3/QUIC: Connection IDs, początkowe straty, przywracanie strat, profil QPACK, zmienność RTT.
- Heurystyki TCP/IP: MSS, okna, znacznik czasu, SACK, rzadkie kombinacje flag oraz równomierne rozkłady portów w przypadku CGNAT.
- ASN/geografia/prefiks: dopasowanie sieci komórkowych AS, datacenters, sieci korporacyjne; pokrycia z znanymi pulami automatyzacji.
Klient i system
- Client Hints i User-Agent: w 2026 roku zaufanie przeszło na CH; niespójności między UA a CH stanowią istotny wyzwalacz.
- WebGL/Canvas/Audio: stabilność fingerprintów renderujących, hałas, sterowniki, cechy GPU, zachowanie w złożonych scenariuszach.
- Navigator/HardwareConcurrency/Memory: przeciwdokształcanie rdzenia-pamięci-typ urządzenia i profil zużycia energii.
- Timings renderowania: sekwencja requestAnimationFrame, częstotliwość klatek, mikrooOpóźnienia GC, EventLoop jitter.
- Składowiska i znaczniki: ciasteczka, Storage, wersje indeksowe, semantyka rekeying między zakładkami i czasem.
Behawioralne
- Trajektorie kursora i przewijania: ciągłość, inercja, „naturalne” zatrzymania, odpowiedź na nieprzewidywalne elementy.
- Kadencja klawiatury: interwały, błędy, poprawki, zachowanie IME i kombinacje klawiszy.
- Wzorce nawigacji: głębokość przeglądania, powroty, gęstość interakcji, przerwy przed działaniem docelowym.
Detekcja ML w 2026 roku
- Wielowarstwowe skoringowanie: szybkie liniowe sprawdzenie, następnie GBDT/sieć neuronowa na agregowanych cechach i, jeśli to konieczne, sekwencyjny model na zdarzenia (transformer/poteżne reprezentacje).
- Cechy grafowe: więzi IP-odcisk-ciasteczka-urządzenie z antysymbolicznymi metrykami trwałości. Wykrywanie „rodzin” botów.
- Dryft i adaptacja: online monitorowanie metryk dryftowych, ręczne i półautomatyczne rollback/roll-forward, stała walidacja A/B.
- Polityki kontekstowe: ten sam wynik może prowadzić do różnego działania w zależności od strony (login vs katalog) i kategorii klienta (nowy vs lojalny).
Praktyka 1: Budujemy mapę sygnałów i scenariuszy pomiarów
Dlaczego potrzebna jest mapa sygnałów
Mapa sygnałów to inwentaryzacja tego, które sygnały są ważne dla twojej branży i scenariuszy użytkowników. Pomaga ona koordynować politykę antybotową pomiędzy bezpieczeństwem, produktem i marketingiem, aby zminimalizować ryzyko blokowania prawdziwych użytkowników.
Kroki
- Określ krytyczne ścieżki: logowanie, rejestracja, wyszukiwanie, koszyk, płatność, metody API. Dla banków — autoryzacja i przelewy, dla biletów lotniczych — wyszukiwanie i rezerwacja, dla bukmacherów — rejestracja oraz wpłaty/wypłaty.
- Dopasuj sygnały: gdzie ważniejsze są metryki behawioralne, a gdzie niskopoziomowe odciski. Na przykład w przypadku logowania i płatności sygnały behawioralne są szczególnie wrażliwe.
- Określ KPI: docelowe wskaźniki blokad, udział nieznanych, częstotliwość wyzwań, średni czas do rozwiązania, udział eskalacji do ręcznego rozpatrzenia.
- Zbierz dane z rzeczywistego ruchu: w tym telemetrię błędów, powroty, wskaźniki na każdym etapie lejka.
- Określ grupy kontrolne: regiony, nowe/powracające, urządzenia/przeglądarki, sieci mobilne/stacjonarne.
Checklist mapy sygnałów
- Obecność inwentaryzacji używanych sygnałów i osoby odpowiedzialnej za ich interpretację.
- Granice poprawności: które rozbieżności są uznawane za normalne w twojej publiczności.
- Plany testów dla każdego krytycznego szlaku.
- Budżet na fałszywe alarmy i interwały rewizji.
Praktyka 2: Legalne testowanie i QA z uwzględnieniem polityk antybotowych
Ramki etyczne i prawne
Wszystkie testy, obciążenia, parsowanie i automatyzacja muszą być przeprowadzane na podstawie przepisów prawnych i uzgodnień. Dla zewnętrznych stron — pisemne pozwolenie lub umowa, dla twoich systemów — koordynacja z bezpieczeństwem i eksploatacją. Przestrzegaj warunków użytkowania, nie wyrządzaj szkód i nie imituje użytkownika tam, gdzie nie ma celu testowania.
Kroki procesu
- Uzgodnienie z właścicielem perimetru: okno testowe, limity RPS, lista IP/ASN, scenariusze i dane do identyfikacji w logach.
- Ustawienie środowiska: stojak lub produkcja z ograniczonym wpływem; dla produkcji — „łagodne” polityki, whitelisting testowych kont i znaczników zapytań.
- Telemetria: włączenie rozszerzonego logowania zdarzeń Bot Managera i proxy logów do SIEM/obserwowalności dla krzyżowego sprawdzenia.
- Punkty kontrolne: rejestrowanie false positive/false negative, korelacja z sygnałami i działaniami (allow/challenge/block).
- Retrospektywy: analiza złożonych przypadków, aktualizacja mapy sygnałów oraz uczenie modeli, jeśli uczestniczysz w współtworzeniu.
Praktyczne wskazówki
- Użyj znaczników testowych zapytań (specjalne nagłówki i protokoły powiadamiania) dla ułatwienia analizy.
- Dla powtarzalności — zapisuj wersje przeglądarek, systemu operacyjnego, typ połączenia.
- Utrzymuj ostrożność w przypadku asynchronicznej nawigacji: rejestruj kroki i czas.
Praktyka 3: Emulacja klienta do analiz i testów funkcjonalnych
Zasady poprawnej emulacji
- Spójność stosu: platforma, wersja przeglądarki, czcionki, język, strefa czasowa, format czasu i układ klawiatury muszą być zgodne.
- Naturalne czasy: wprowadzanie, przewijanie i kliknięcia w tempie porównywalnym do ludzkiej interakcji, bez nagłych szczytów i syntetycznych wzorców.
- Stabilne profile Web API: odciski renderujące i odciski audio nie powinny chaotycznie „skakać” między krokami sesji.
- Sesje i ciasteczka: utrzymanie kontekstu między stronami i zakładkami tam, gdzie to oczekiwane.
Kroki konfiguracyjne dla testu funkcjonalnego
- Wybór referencyjnego urządzenia: określ docelową przeglądarkę i platformę twojej głównej publiczności.
- Sprawdzenie odcisku: wygeneruj i zapisz wzorcowe parametry za pomocą narzędzia do generacji odcisku przeglądarki, a następnie upewnij się, że środowisko testowe reprodukuje porównywalne wartości.
- Profil sieciowy: ustaw charakterystyczne dla publiczności opóźnienia i jitter, aby czasy zdarzeń były realistyczne.
- Kroki odtwarzania: zarejestruj sekwencję działań i opóźnienia, aby zapewnić powtarzalność wyników i analizować logi antybota.
Checklist emulacji
- UA i Client Hints są zgodne, strefa czasowa odpowiada geografii.
- Ekran i gęstość pikseli są porównywalne z docelowym urządzeniem.
- WebGL/Canvas inicjalizacja jest przewidywalna, renderowanie nie „skacze” między wizytami bez powodu.
- Sygnały wejściowe są rejestrowane bez nadludzkiej szybkości.
Praktyka 4: Warstwa sieciowa — mobilne IP z CGNAT w porównaniu do datacenters, rotacja i kontrola jakości
Dlaczego mobilne IP z CGNAT są postrzegane jako bardziej lojalne
- Reputacja ASN: operatorzy sieci komórkowych mają „bazową użytkownikową” reputację, podczas gdy niektóre datacenters są skorelowane z automatyzacją i skryptami.
- Dynamika CGNAT: wspólne IP dla wielu abonentów generuje wysoki „naturalny” poziom legalnej aktywności; sygnały są powiązane z żywymi użytkownikami.
- Heurystyki sieciowe: charakterystyczne wahania RTT, jitter, cechy radiowej sieci i rozkładu portów są postrzegane jako organiczne.
Kiedy adresy z datacenters są uzasadnione
Dla wewnętrznych testów w kontrolowanym środowisku, gdy ważna jest przewidywalność i stabilność ścieżek. Zewnętrzne integracje z jasną polityką whitelist również często odbywają się na adresach DC zgodnie z umową.
Rotacja i trwałość
- Rotacja według timera/API: unikaj nadmiernej częstotliwości zmiany adresów dla scenariuszy wielostopniowych. Sesja powinna być ciągła.
- Geograficzna i ASN-stabilność: dla porównywalności eksperymentów używaj jednego kraju i, gdy to możliwe, tego samego operatora.
- Jakość połączenia: monitoruj straty, opóźnienia oraz prędkość, aby wykluczyć anomalia sieciowe jako przyczyny problemów.
Praktyczna uwaga
Do uczciwego monitoringu, QA oraz zadań analitycznych w rzeczywistym kontekście mobilnym wygodne są mobilne proxy oparte na kartach SIM. Ważne, aby dostawca wspierał jednoczesne protokoły HTTP(S) i SOCKS5, rotację według timera i przez API, szeroką geolokalizację i całodobowe wsparcie. Odpowiednim przykładem takiej usługi będzie MobileProxy.Space: prawdziwe karty SIM, 218+ mln IP w 53+ krajach, elastyczna rotacja według timera, API i linku, 3 godziny darmowego testu oraz wsparcie 24/7. Dla pierwszego zakupu obowiązuje kod promocyjny YOUTUBE20 z rabatem 20%.
Praktyka 5: Strategie dla różnych kategorii stron
Banki
- Fokus: autoryzacja i transakcje. Wysoka wrażliwość na biometrię behawioralną i integralność urządzenia.
- Taktyka testowania: minimalne obciążenia, jasno określone okna testowe, przypisane IP i uzgodnione scenariusze logowania.
E-commerce
- Fokus: katalog, koszyk, promocje. Równowaga pomiędzy UX a przeciwdziałaniem masowemu scrapowaniu.
- Taktyka: rotacja polityk A/B w mniej ryzykownych sekcjach, telemetria wpływu wyzwań na konwersję.
Bilety lotnicze
- Fokus: wyszukiwanie i rezerwacja; ochrona taryf i pamięci cenowej.
- Taktyka: ograniczenia częstotliwości jednolitych zapytań, wzmocniona weryfikacja przy masowych wyszukiwaniach w pobliżu dat.
Bukmacherzy
- Fokus: rejestracja, bonusy, linie zakładów.
- Taktyka: wzmocniona weryfikacja nowych urządzeń, wzorce behawioralne przed i po rejestracji, dynamiczne polityki dla wydarzeń szczytowych.
Praktyka 6: Metryki jakości i operacyjna kontrola
Co mierzyć
- Udział podejrzanego ruchu: trendy w segmentach (ASN, region, urządzenie).
- False Positive/Negative: odsetek błędnie zablokowanych osób i przepuszczonych botów.
- Wskaźnik przechodzenia wyzwania: jak często legalni użytkownicy przechodzą kontrole bez problemów.
- Wpływ na lejek: zmiana CR, porzucone koszyki, odmowy logowania.
Procesy
- Comiesięczne przeglądy: incydenty, skoki, porównanie z grupami kontrolnymi.
- Retrospektywy modeli: analiza dryftu cech, bezpieczeństwo dostaw cech.
- Kooperacja: bezpieczeństwo, produkt, marketing i eksploatacja z jednolitymi pulpitami reklamacyjnymi.
Praktyka 7: Wzorce infrastrukturalne integracji i testowe środowiska
Warstwy integracji
- Perimetr CDN/WAF: podstawowe rozwiązanie i lekkie polityki dla niskiej latencji.
- Aplikacja: uzyskiwanie szczegółów dla subtelnej logiki biznesowej na krytycznych krokach.
- Analiza: eksport telemetrii do magazynów zdarzeń i SIEM dla pełnej korelacji.
Testowe środowiska
- Staging: sprawdzenie kompatybilności czujników, stabilności fingerprintów między wydaniami.
- Canary settings: ostrożne uruchamianie nowych reguł na części ruchu z szczegółowym porównaniem metryk.
- Chaos tests: symulacja utraty sieci i opóźnień, aby zrozumieć trwałość rozwiązań.
Typowe błędy i jak ich unikać
- Przeregulowanie w przypadku jednostkowych incydentów: prowadzi do wzrostu fałszywych alarmów. Rozwiązanie: wartość na reprezentatywnych danych.
- Ignorowanie dryftu: cechy i zachowania użytkowników się zmieniają. Rozwiązanie: regularne przeglądy zasad i modeli.
- Brak spójności pomiędzy zespołami: różne KPI prowadzą do konfliktów. Rozwiązanie: jednolita macierz metryk i wspólny plan implementacji.
- Błędna rotacja IP: zbyt częsta zmiana bez uwzględnienia sesji psuje scenariusze. Rozwiązanie: rotacja z uwzględnieniem długości zadań.
- Losowe niezgodności fingerprinta: sprzeczne języki/strefy czasowe/ekran. Rozwiązanie: checklisty spójności.
Narzędzia i zasoby do pracy
Wewnętrzne
- Pulpity antybotowe: podziały według sygnałów, działań, modeli.
- Obserwowalność: centralne pulpity opóźnień, błędów, przepustowości.
- Regulacje: regulaminy dotyczące testów, rozwiązania architektoniczne, podręczniki incydentów.
Wsparcie
- Sprawdzenie IP i DNS: upewnij się, że parametry sieciowe odpowiadają oczekiwaniom twojej docelowej publiczności i nie zawierają wycieków DNS w twoich testach.
- Walidacja proxy: waliduj dostępność, protokoły i podstawowe opóźnienia węzłów proxy przed uruchomieniem scenariuszy.
- Kalkulator proxy i mapa opóźnień: planuj budżety i wybieraj optymalne regiony i operatorów na podstawie RTT.
- Generator odciska przeglądarki: rejestruj wzór i sprawdzaj stabilność profilu w trakcie wydań.
Podkreślamy, że część tych narzędzi jest dostępna w ekosystemie MobileProxy.Space: sprawdzanie IP, test DNS Leak, Proxy Checker, kalkulator proxy, mapa opóźnień oraz generator fingerprintów przeglądarki pomogą przyspieszyć przygotowania do testów. W połączeniu z ich mobilnymi proxy (HTTP(S) oraz SOCKS5 jednocześnie, rotacja według timera, API i linka) to spełnia podstawowe potrzeby infrastrukturalne dla poprawnego QA.
Przykłady i wyniki: jak to działa w praktyce
Przykład 1: E-commerce i wzrost scrapowania
Problem: wzrost zapytań do katalogu, skoki w kosztach CDN i pogorszenie wyszukiwania. Działania: ulepszono mapę sygnałów dla katalogu, wzmocniono priorytetyzację HTTP/2 i wzorce behawioralne dla listingu, przeprowadzono A/B na 10% ruchu. Wynik: zmniejszenie podejrzanych zapytań o 38%, utrzymanie konwersji w koszyku, zmniejszenie latencji p95 o 12% dzięki tarpitom zamiast całkowitego zakazu.
Przykład 2: Bank i podatny login
Problem: fala credential stuffing. Działania: zwiększona wrażliwość na niezgodności UA/CH, wzmocnienie weryfikacji sesji, łagodne wyzwania w nocy dla nowych urządzeń w wrażliwych regionach. Wynik: zmniejszenie nieudanych logowań o 44%, brak wzrostu zgłoszeń do wsparcia dzięki łagodnym kontrolom.
Przykład 3: Bilety lotnicze i monitorowanie cen
Problem: masowe wyszukiwanie bliskich dat, nadmierne obciążenie na pamięci podręcznej i metaprzeszukiwanie. Działania: dynamiczne polityki w zakresie dat i częstotliwości; podział scenariuszy na informacyjne i transakcyjne. Wynik: zmniejszenie zapytań o 29% przy stabilnym poziomie udanych rezerwacji, wzrost dokładności prognoz popytu.
Przykład 4: Bukmacher i nadużycia bonusowe
Problem: duża liczba rejestracji o krótkim cyklu życia. Działania: dodano sekwencyjny model na zdarzenia przed i po rejestracji, wzmocniono spójność fingerpintów oraz weryfikację mobilnych sygnałów. Wynik: minus 35% podejrzanych kont, oszczędności na bonusach i zmniejszone obciążenie moderacji.
FAQ: trudne pytania i precyzyjne odpowiedzi
Jak połączyć polityki antybotowe z UX?
Ustal poziomy wrażliwości według stref ryzyka, mierz wpływ na konwersję i stosuj łagodne działania tam, gdzie zablokowanie nie jest krytyczne. Regularna walidacja A/B jest obowiązkowa.
Dlaczego mobilne IP są często „uczciwsze” w testach rzeczywistej publiczności?
Odbijają „żywą” dynamikę sieciową CGNAT i mobilne ASN, co pokrywa się z zachowaniem części twoich rzeczywistych użytkowników. To szczególnie przydatne w walidacji UX.
Czy można całkowicie polegać na sygnałach behawioralnych?
Nie. Sygnały są silne w transakcjach i logowaniu, ale wrażliwe na fałszywe alarmy przy niestabilnej sieci lub dostępności. Potrzebna jest kombinowana ocena.
Co robić w przypadku wzrostu fałszywych blokad?
Pobierz dane telemetrii, cofnij ostatnie zasady, włącz łagodzące polityki i przeprowadź retrospektywę dla kohorty z błędami.
Jaki jest optymalny interwał rotacji IP?
Dostosuj do długości scenariusza. W przypadku procesów wielostopniowych używaj stabilnego adresu przez całą sesję; zmieniaj zgodnie z zadaniem lub według timera z zapasem czasowym.
Czy należy ujednolicić przeglądarki w testach?
Tak, dla powtarzalności zapisuj wersje i platformy. Ale okresowo sprawdzaj alternatywne stosy, aby zobaczyć zachowania krańcowe.
Jakie są korzyści z mapy opóźnień i sprawdzania DNS?
Pomagają one wykluczyć anomalia sieciowe jako przyczyny fałszywych wniosków i wybrać geografię o najmniejszym ryzyku problemów.
Jak pracować z robotami partnerskimi (good bots)?
Ustanów listy białe, tokeny i kontrakty; zapewnij im stabilne okna wywołań oraz identyfikację dla przejrzystego audytu.
Jakie są główne trudności detekcji ML w 2026 roku?
W dryfcie i aktualizacji zachowań użytkowników oraz atakujących: potrzebne jest trwałe przechowywanie cech, procedury antydryftowe i szybka walidacja A/B zmian.
Podsumowanie: strategia na 12 miesięcy
Silna strategia antybotowa w 2026 roku to nie zbiór „sekretów”, a systemowa inżynieria: mapa sygnałów, koordynacja zespołów, wielowarstwowe skoringowanie ML oraz elastyczne polityki, różne dla logowania, katalogu, koszyka i płatności. Praktyki legalnego testowania z uzgodnionymi oknami oraz stabilnymi profilami sieciowymi mogą poprawić zabezpieczenie без szkody dla UX. Mobilne IP z CGNAT często bardziej odpowiadają rzeczywistemu krajobrazowi użytkowników, a adresy z datacenters pozostają użyteczne w kontrolowanych scenariuszach i listach białych. Używaj narzędzi do sprawdzania IP, DNS i odcisków, mapy opóźnień oraz kalkulatorów dla przewidywalności eksperymentów. Organizuj comiesięczne retrospektywy, kwartalne przeglądy modeli i trzymaj fokus na wpływie działań na lejek. Tak, usługi infrastrukturalne z prawdziwymi kartami SIM i dużą liczbą adresów, takie jak MobileProxy.Space, pomogą zbudować sieć warstwową dla QA i monitorowania. Nie zapomnij o ich 3-godzinnym teście i kodzie promocyjnym YOUTUBE20: jest to przydatne, gdy planujesz budżet i pilotaż w kilku krajach przy jednoczesnym wsparciu HTTP(S) oraz SOCKS5, rotacji według timera, API lub linku. W rezultacie wszyscy zyskują: bezpieczeństwo — dzięki dokładności, produkt — dzięki stabilnej konwersji, a użytkownicy — dzięki płynnemu i przewidywalnemu doświadczeniu.
